I recently took part in a discussion that brought to light the most unusual argument against having a monolith that I have ever heard - that a monolith is a single point of failure.
I want to make clear that I consider monoliths and microservices neither good nor bad, or universally better or worse at any particular job. To me these architectures are just tools that work better in some settings and worse in others. As I explained in “Misguided Mark misrepresents Micro-services“, to me they are just paradigms - different ways to see and explain the same thing.
The details of the discussion aren’t important for debunking the argument. The important thing is that the discussion was centered around should a new feature be added to a monolith or should it be a microservice.
We covered quite a few common arguments for microservices all of which fell apart when examined. And then the other side brought up that having a monolith is a single point of failure.
This argument shows a deep misunderstanding of what microservices are and how they work.
People usually think about monoliths in terms of classes and methods (or modules and functions), but they think about microservices in terms of services and APIs.
Services and APIs are the same thing as classes and methods.
They are two sides of the same coin - on one side everything is in one program, on the other each class is its own program.
In other words, they are two paradigms through which people build and think about applications. They are talking about the same thing just from different perspectives.
If you have a monolith in which a call to the process method on the class Payment internally calls the authorize method on class User, then you have two places where something can go wrong. Either Payment#process can error or User#authorize can error. In both cases the call to Payment#process has erred.
If you have microservices in which a request to the process_payment API on the Payment microservice internally makes a request to the authorize_token API on the User microservice, then you have two places where something can go wrong. Either the request to process_payment on the Payment service returns a 500 or the request to authorize_token on the User service returns a 500. In both cases the request to process_payment on the Payment microservice has erred.
The number of failure points is the same.
Though in reality, the microservices example has two more failure points because each request to a service can also fail due to various problems - like a misconfigured load balancer, or the machine running out of file descriptors, or a congested router in the data center, or any other reason a network request might fail…
So where does this single point of failure argument come from?
I believe that Netflix and a simple case of not thinking with your own head are the source of this odd argument.
As most programmers know, Netflix is a big proponent of microservices. They have been making headlines across various sites popular in the IT industry how microservices have enabled them to weather any outage. They even made a tool called Chaos Monkey that turns off services at random to test how resilient your system is.
So if it works for Netflix why wouldn’t it work for us? Right?
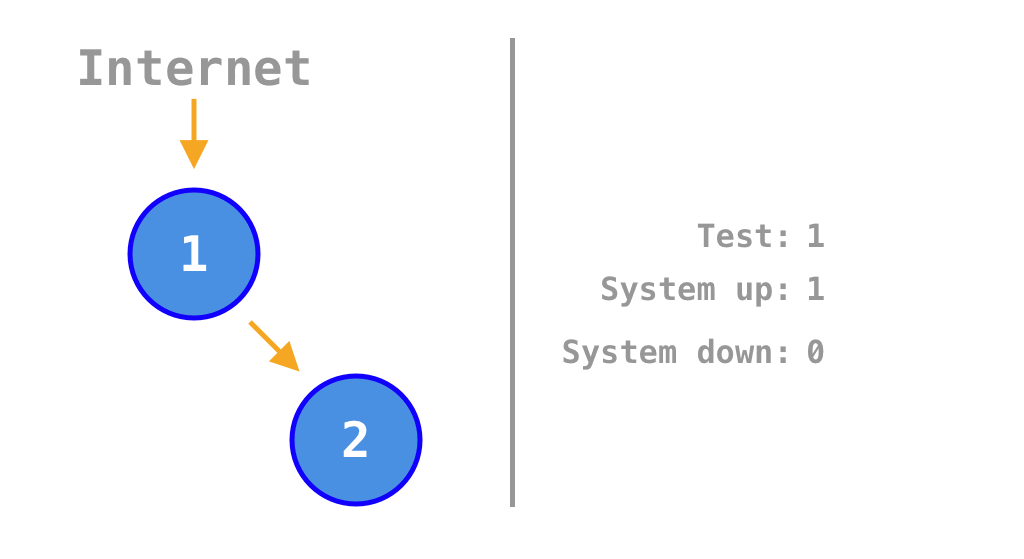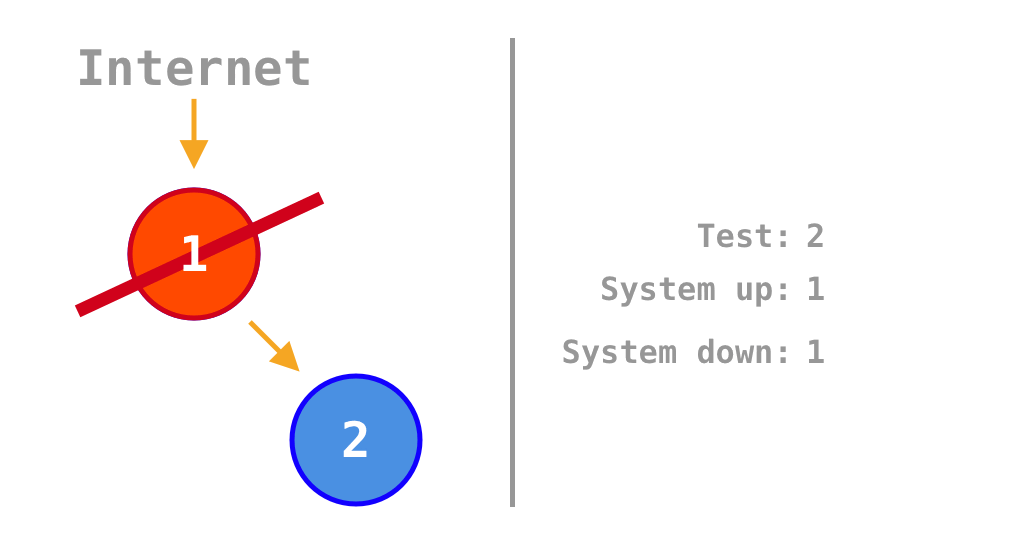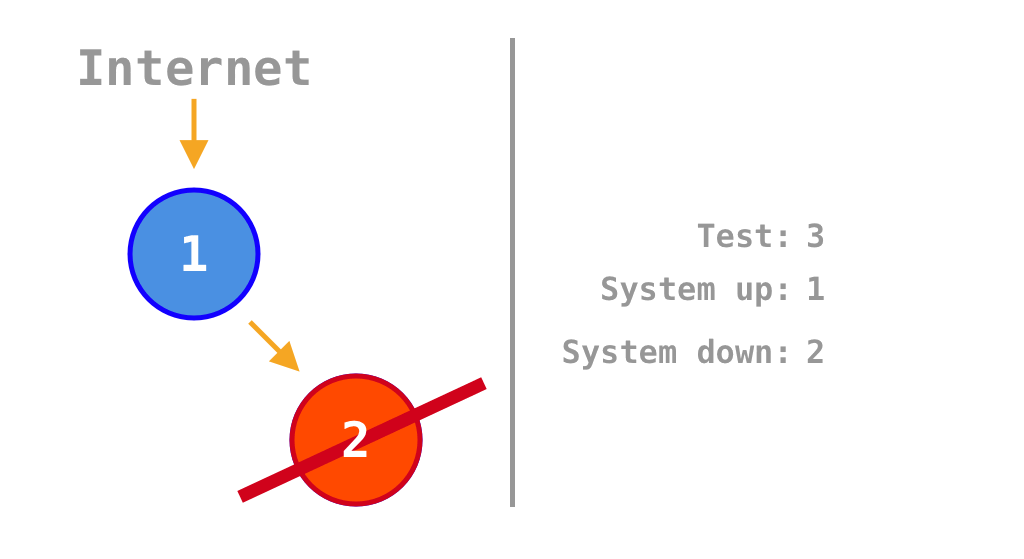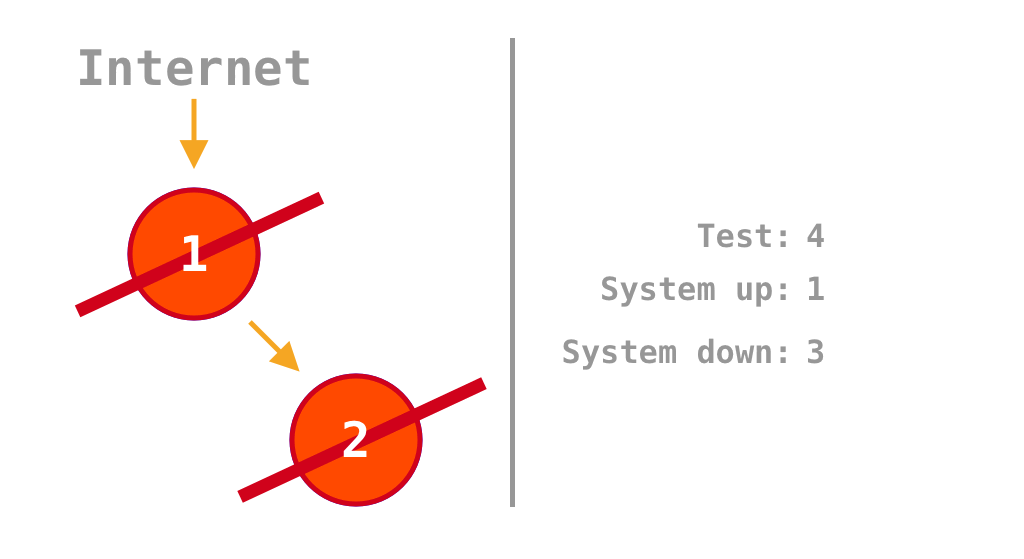
Let’s apply Chaos Monkey to our example with two services and see.
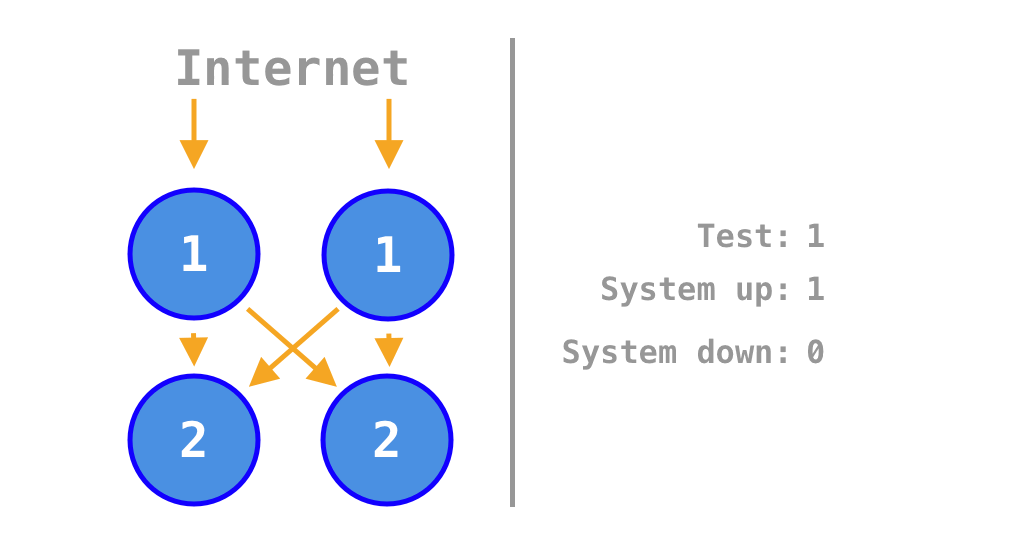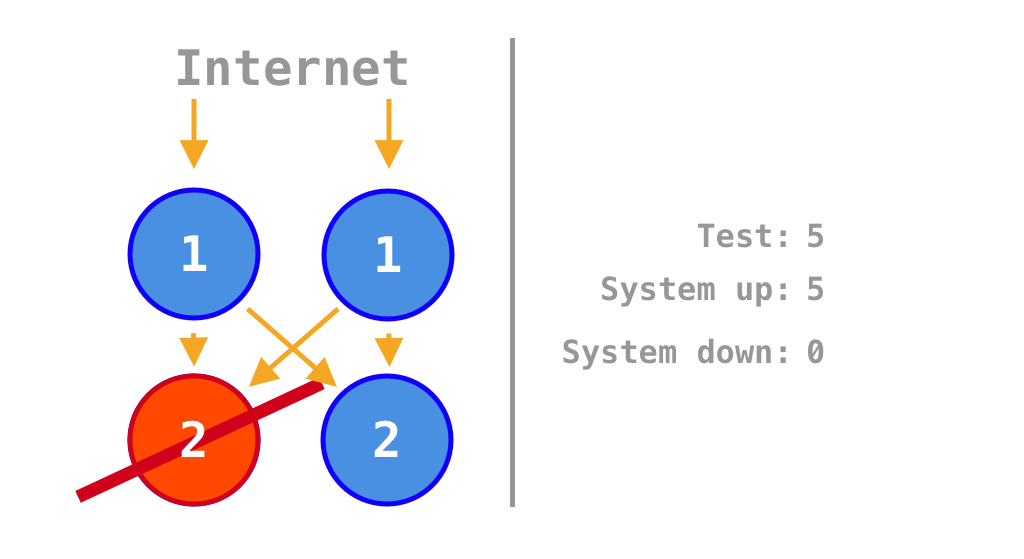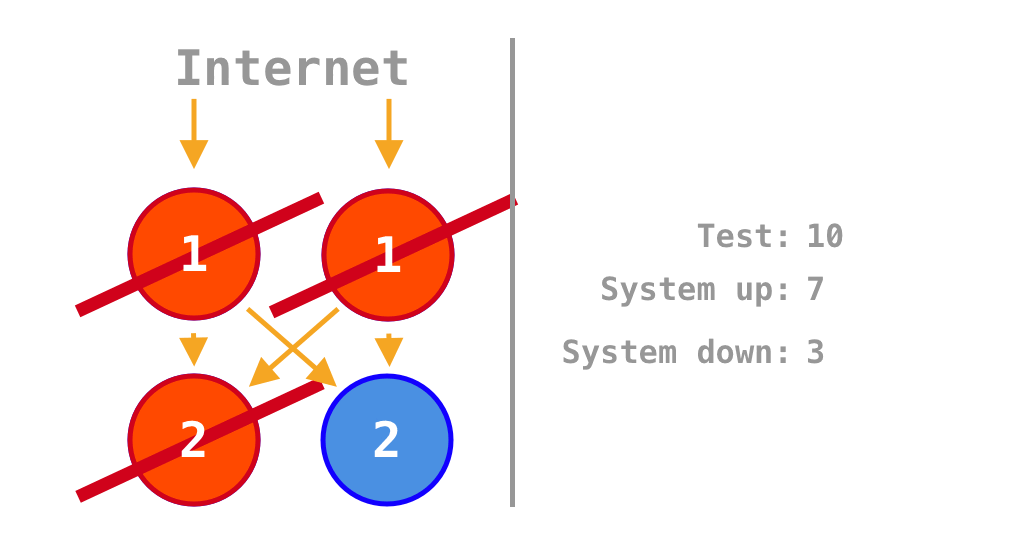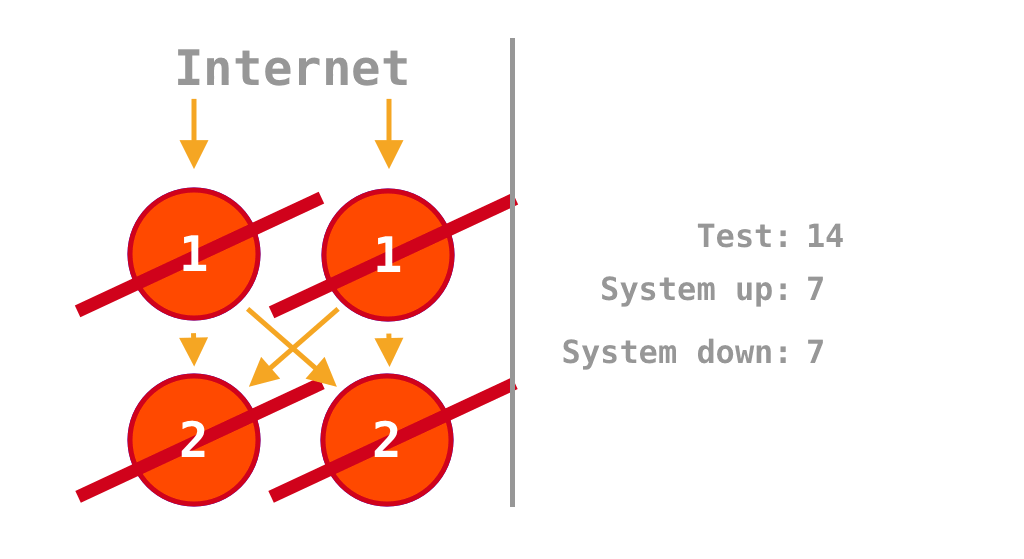
If all services are on, payment processing works. But if one or both are turned off, payment processing fails. It can process payments only 25% of the time. A monolith would perform much better, it can either be on or off meaning that it can process payments 50% of the time.
Animation that shows in which scenarios the system is up or down depending on which of the two services is on or off
What gives? Maybe if we had two of every service it would be more resilient?
Animation that shows in which scenarios the system is up or down depending on which of the four services is on or off
It would, but only 50% of the time. A monolith would perform much better, as it would fail to process the payment only when all instances are off which means it would process payments 75% of the time.
The point of Chaos Monkey is to test how resilient your architecture is. It works with services because Netflix is invested in microservices and they have built a tool to test the resiliency of their architecture.
But architecture is so much more than microservices or monoliths. It’s how flexible the system is, how easily it can be extended, how easily a team can maintain it, and how resilient it is to failure.
The fact that Netflix has built a resilient architecture with microservices doesn’t mean that you can’t achieve the same with other architectures.
Resilience to failure can be addressed both in microservices and in monoliths through the same patterns - circuit breakers, policies/strategies, and others.
I have an RSS feed, if you want to receive future posts