RabbitMQ is more than a Sidekiq replacement

I got inspired to write this post by the overwhelming response I received for my talk at the local Ruby user group.
Why do we need Sidekiq or RabbitMQ?
"Background job" libraries like Sidekiq are used in situations when the result of a process can be yielded, but further side effects still need to be caused.
An example of this are signup forms. When a user signs up, usually, a confirmation email is sent out to confirm their email, but the email is not crucial to the signup process — the user's account will be created even if the confirmation email fails to get sent.
It's unclear what to do if the email fails to get sent. The intuitive solution would be to return an error, but then the user wouldn't be able to create a new account since their email is already taken. We are penalizing the user for something that isn't their fault, something they can't influence and something that has no effect on the action they wanted to undertake. If we decide to retry the action we end up with the same problem as before if it fails again.
To resolve those issues we offload that work to a "background job" library. In the case of the signup example, the user's account would be created and they would be logged in. The "send email" job would be put in a queue, and would eventually get processed. If the job fails we can retry it as many times as we like, or run custom logic on the raised errors. The user isn't penalized for our mistake.
But do we really need Sidekiq for this? No. The same functionality can be accomplished with the standard Queue class and a Thread.
class App < Roda JOBS = Queue.new Thread.new do loop do begin job = JOBS.pop job.call rescue => e puts "ERROR: #{e}" JOBS << job end end end route do |r| r.on 'sign_up' do r.post do email = r.params['email'] JOBS << proc do Mailer::ConfirmationMailer.deliver(email) end end end end end
Why do we use background workers then?
The above approach has many downsides. Not to go too deep down the rabbit hole, I'll focus on debuggability (yes, I made that word up), persistence, scaling and lastly fault tolerance.
The above solution is difficult to debug. There is no clear way to inspect the contents of the queue without littering the code with bindings to pry. If the server is stopped (e.g. to add said bindings to pry) all jobs in the queue are lost, which means that we can't even extract the job that caused the issue to replicate it. To solve those issues Sidekiq uses Redis to store it's jobs. Redis is an in-memory key-value store that can store values as many different data types. Jobs are stored in a list as JSON objects. We can inspect the queue's content by connecting to Redis with redis-cli and inspecting the queue list.

Sidekiq's memory problem
There are two concerns regarding fault tolerance, Redis and the worker process. By default, Redis is a volatile store (data may be lost if the store restarts), though that can be changed by utilizing its RDB and AOF features which in conjunction prevent any data loss. There are some caveats, if RDB (which is enabled by default) is used without AOF, data loss may still occur, and if used in conjunction with AOF may cause performance fluctuations.
When it comes to worker failures, Sidekiq handles most issues regarding handling Ruby errors and retry logic. But if a worker crashes or is killed while processing a job, that job is gone.


If we ignore the fault tolerance pay wall, Sidekiq still has a memory consumption issue as it uses Redis for its job queue. Redis, is an in-memory data store, and it has no mechanism to offload stale data to disk. This means that all jobs in the queue are kept in-memory all the time.

How RabbitMQ solves those issues
RabbitMQ is a general purpose message queue. To utilize it in a "background worker" backend scenario we need a library to communicate with it. I would highly recommend Sneakers for this purpose. Sneakers handles worker process creation, management, queue creation, and job enqueuing — everything that Sidekiq does, and offers a syntax that resembles Sidekiq's syntax.
class SneakersLogger include Sneakers::Worker # Defines the queue and it's options from_queue 'loggings' def work(log_message) Logger.log(log_message) # Does magic that will be explaned in the next section ack! end end # --- class SidekiqLogger include Sidekiq::Worker def perform(log_message) Logger.log(log_message) end end
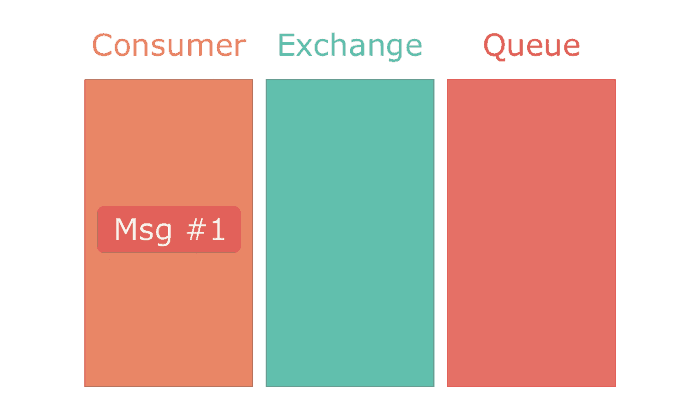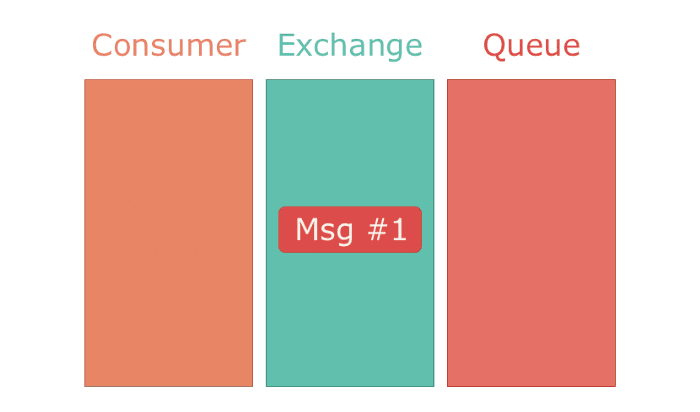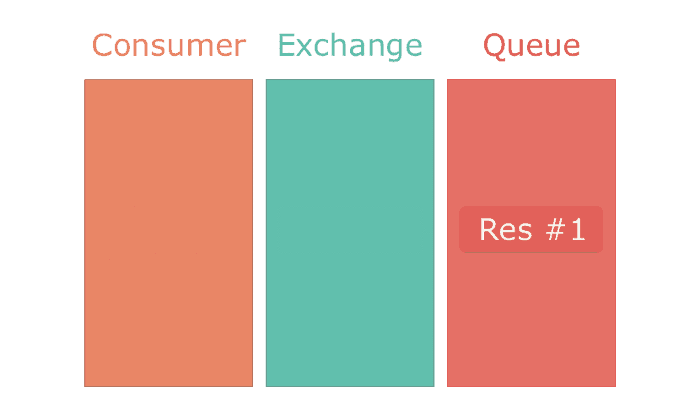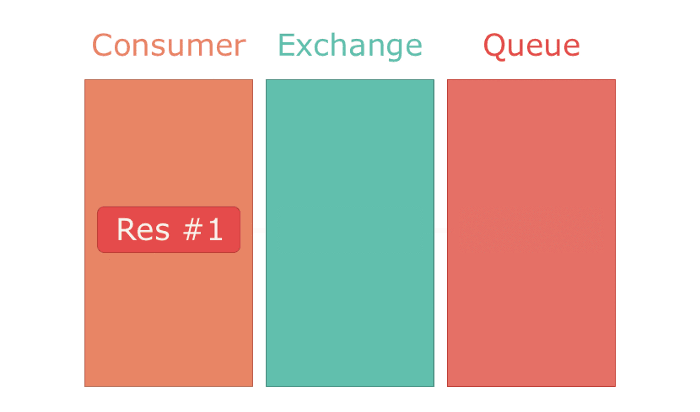
The biggest difference between the two implementations is the ack! on line 10. That line enables Sneakers and RabbitMQ to guarantee that a job has been processed. This is a feature of RabbitMQ's communication protocol — AMQP. In AMQP a message can be popped from a queue in two modes — ack mode and no-ack mode.
Another difference is memory consumption. By default, RabbitMQ keeps as many messages in memory as it can, before it reaches a configurable high water mark. At that point it offloads all eligible messages to disk. Though, that is not true for all queues. RabbitMQ also provides a "lazy queue" which keeps all it's messages on disk if possible — it's useful for passing large messages.

There is still one feature of Sidekiq I haven't mentioned — the UI. Sidekiq's UI is useful for monitoring the health of your jobs, and general throughput.


Exchanges
AMQP defines the concept of exchanges. Exchanges can be thought of as routers. When a message is published to an exchange, the exchange determines which queues should the message be delivered to. It's important to note that it's impossible to put a message directly into a queue. Even if a message is published directly to a queue, a temporary exchange will be created to deliver it to the queue.
There are four types of exchanges supported by RabbitMQ.
The most commonly used exchange type is the direct exchange. It directly delivers all messages to a single queue bound to it. It's a 1-on-1 mapping of an exchange to a queue. If applied to a chat application, a direct exchange would deliver messages from a chat room to a single user.


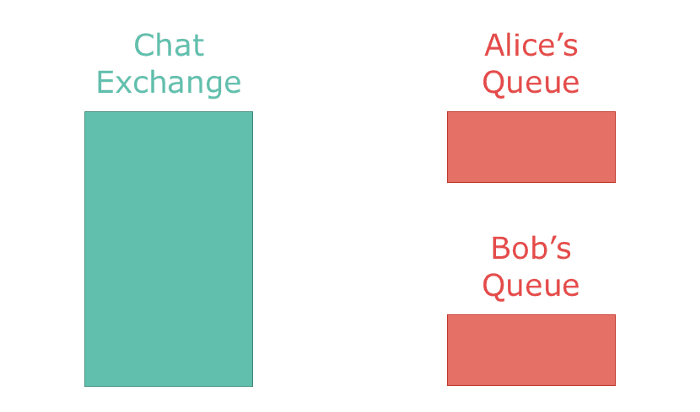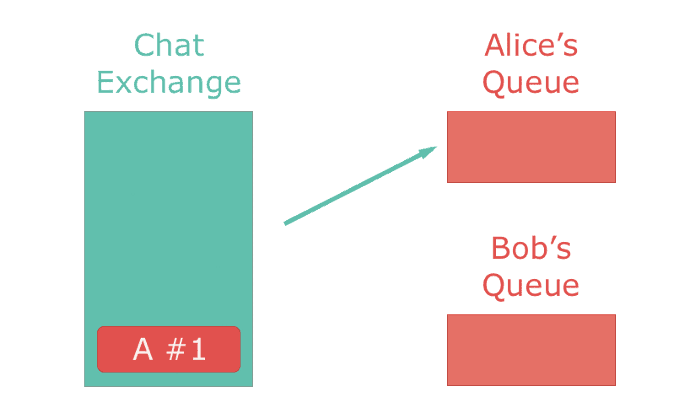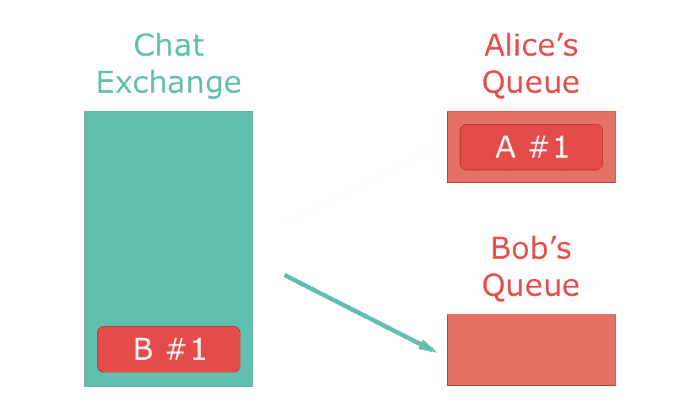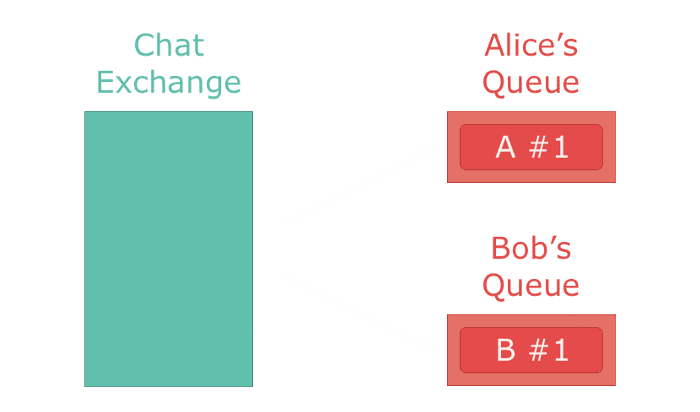
Utilizing exchanges gives many advantages — exactly once delivery, performance, and ease of deprecation. Utilizing an exchange to deliver your messages is much faster and more reliable than using Ruby to handle that logic. There is also the pragmatic reason of not having code to maintain. The logic is handled by RabbitMQ, you only have to configure it (which can be done through code). Exchange-exchange and exchange-queue bindings can be changed on-the-fly by any client which enables one application to change the behavior of other services. Personally, exchanges have helped me deploy applications with little-to-no downtime and deprecate services without having to change other services.
Special features
RabbitMQ adds it's own magic on top of AMQP. I have already mentioned header exchanges, which are a non-standard AMQP feature. A feature I personally use a lot is "direct reply-to". Direct reply-to is a form of synchronous communication between a producer and a consumer. It enables a producer to publish a message and wait for a consumer to process it and return the result directly to the producer. It's useful when the result of a message is used in further processes. E.g. IoT devices usually log a heartbeat signal to their server to indicate that they are connected and configured correctly. If we have a smart lock, we can process its heartbeat asynchronously since the result isn't really important for the server nor for the device. But a pin check is important and should be handled synchronously to avoid access permission errors caused by stale data.


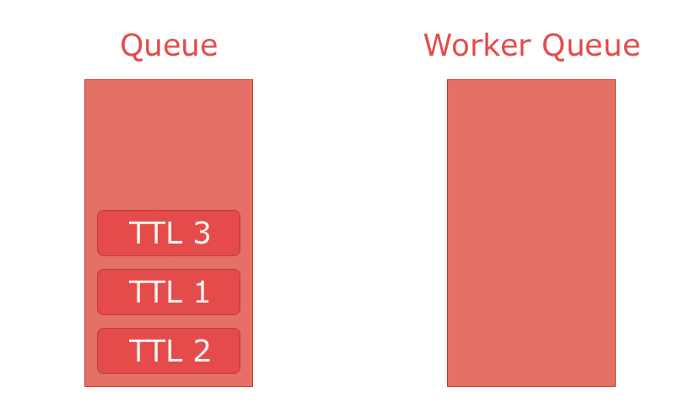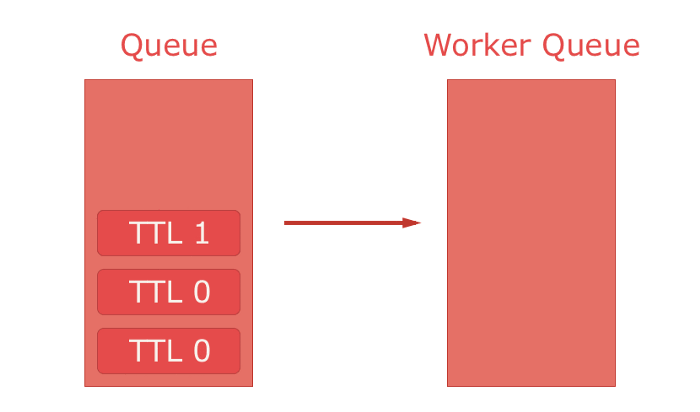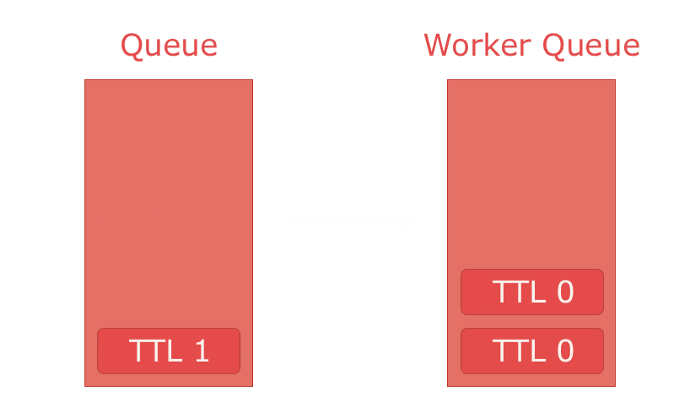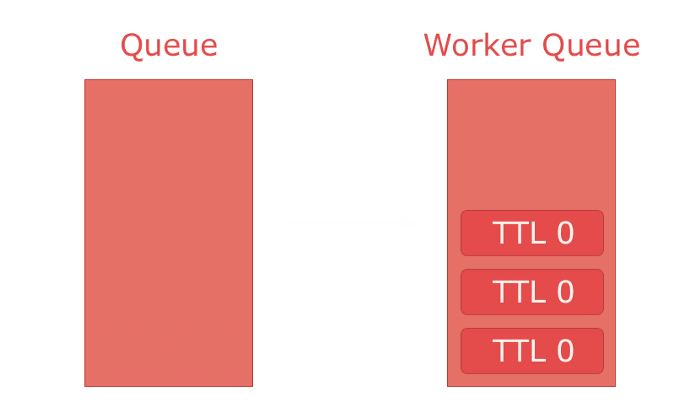
Finally there is "TTL". It specifies how long a message lives. If a message outlives its TTL it's automatically rejected from the queue. Though, this feature comes with a caveat — this rule can only be enforced for the message at the front of the queue. E.g. if you put two messages in a queue the first with a TTL of 300 and the second with a TTL of 100. Both would be in the queue until the one with a TTL 300 expires, because it is in front. The moment it expires, the second message is at the front and automatically expires since it's TTL has passed. This seems harmless, but can cause a lot of problems when combined with dead lettering to achieve e.g. offset delivery.
Plugins
For me, this is the most important feature of RabbitMQ. With plugins you can add any functionality you want to RabbitMQ. The best example of this is the management console which is a plugin, and must be enabled before use.
Through plugins, RabbitMQ supports not only AMQP, but STOMP, MQTT and WebSockets as communication protocols.
Then there is the Federation plugin. It enables RabbitMQ to run several isolated clusters or instances which can communicate with one-another. It is similar to the way that Mastodon works. All users, no matter which server they signed up to, can communicate with one-another. Federations are useful for handling large workloads. E.g. if you handle logs from a lot of different machines through RabbitMQ, that can be handled by one federated cluster, while everything else is handled by another federated cluster. That way you can scale those two cluster independently depending on their workload, and you avoid the noisy neighbor problem (when a highly taxed service slows the whole system down).

Conclusion
Replacing Sidekiq with RabbitMQ provides many advantages when it comes to debuggability, scaling, fault tolerance and memory consumption. It supports multiple industry-standard message queue protocols and can be used as a drop in replacement for other "background worker" libraries.
If you need a queue that guarantees job execution and persistence, go with RabbitMQ instead of Sidekiq. There are some features that are missing in Rabbit, like cron jobs and unique jobs, but they can be added by the clients. RabbitMQ offers a plethora of features which, if not useful at first, will become useful later as they will help grow a monolith to a services oriented architecture.
To get started take a look at projects like Sneakers (background jobs) and Bunny (AMQP client), read through the basic concepts page, and lastly there is the manual. If you are using Ruby on Rails, Sneakers integrates with ActiveJob which eases the transition.
Sidekiq isn't useless! If your project doesn't require execution or persistence guarantees, or if you hold a Sidekiq Pro license, I would recommend you stick with it for the time being. While I disagree with hiding essential features (like guaranteed execution, and rolling restarts) behind a paywall, a Pro license offers support and additional business oriented features which you won't get with a self-hosted RabbitMQ instance.